Post-competition update
The NeurIPS 2021 ML4CO competition results were presented on December 9th, 2021 during the (virtual) NeurIPS conference. The competition ran from July to November 2021. Congratulations to the winners !
Primal task winners
- global: team CUHKSZ_ATD, 1st on all problem benchmarks
- student: teams UNIST-LIM-Lab (1st) and MixedInspiringLamePuns (2nd)
Dual task winners
Configuration task winners
Ressources
- Proceedings - PMLR paper, contributed papers, and team compositions.
- Youtube videos - Talks given during the NeurIPS event, including the winner presentations, an invited keynote by Kate Smith-Miles, and a panel discussion.
- Datasets - All training and evaluation instances used in the competition, for all three problem benchmarks (Balanced Item Placement, Workload Apportionment and Anonymous). Please cite our PMRL paper if you use these datasets.
- Official github repository - Contains the base code that was used to run the competition.
- Hidden github repository - Contains additional scripts used to generate the benchmark instances, as well as indications to run the evaluation pipeline. Was made public only at the end of the competition.
- Detailled evaluation results - Detailed performance of each team, on each evaluation instance.
Program of the NeurIPS event (registration required):
- 18:45 GMT - NeurIPS Competition Track Day 3 live presentation (20 min)
- 19:05 GMT - ML4CO mini-workshop on Zoom + Gathertown (3 hours)
- 19:05 GMT - Competition wrap-up (15 min)
- 19:20 GMT - Winner presentation: primal task (10 min) - Team CUHKSZ_ATD
- 19:30 GMT - Winner presentation: dual task (10 min) - Team Nuri
- 19:40 GMT - Winner presentation: configuration task (10 min) - Team EI-OROAS
- 19:50 GMT - Poster session on Gathertown (30 min)
- 20:20 GMT - Break (15 min)
-
20:35 GMT - Keynote (30 min) - Kate Smith-Miles
Instance Space Analysis: Machine Learning about Combinatorial Optimisation
Abstract: Instance Space Analysis (ISA) is a recently developed methodology to support objective testing of algorithms. Rather than using machine learning (ML) to replace some components of an optimisation algorithm, it uses ML to gain insights into the strengths and weaknesses of optimisation algorithms under various conditions defined by properties of the test instances. It also provides visualizations of the adequacy of benchmark test suites, and any bias in the chosen test instances, to support algorithmic trust. This talk provides an overview of the ISA methodology, and the online software tools that are enabling its worldwide adoption in many disciplines. A combinatorial optimisation case study on university timetabling is presented to illustrate the methodology and tools. - 21:05 GMT - Panel discussion (1 hour) - Andrea Lodi, Timo Berthold, Frank Hutter, Vinod Nair, Kevin Leyton-Brown
Introduction
The Machine Learning for Combinatorial Optimization (ML4CO) NeurIPS 2021 competition aims at improving state-of-the-art combinatorial optimization solvers by replacing key heuristic components with machine learning models. The competition's main scientific question is the following: is machine learning a viable option for improving traditional combinatorial optimization solvers on specific problem distributions, when historical data is available ?
While most combinatorial optimization solvers are presented as general-purpose, one-size-fits-all algorithms, the ML4CO competition focuses on the design of application-specific algorithms from historical data. This general problem captures a highly practical scenario relevant to many application areas, where a practitioner repeatedly solves problem instances from a specific distribution, with redundant patterns and characteristics. For example, managing a large-scale energy distribution network requires solving very similar CO problems on a daily basis, with a fixed power grid structure while only the demand changes over time. This change of demand is hard to capture by hand-engineered expert rules, and ML-enhanced approaches offer a possible solution to detect typical patterns in the demand history. Other examples include crew scheduling problems that have to be solved daily or weekly with minor variations, or vehicle routing where the traffic conditions change over time, but the overall transportation network does not.
The competition features three challenges for ML, each corresponding to a specific control task arising in the open-source solver SCIP, and exposed through a unified OpenAI-gym API based on the Python library Ecole. For each challenge, participants will be evaluated on three problem benchmarks originating from diverse application areas, each represented as a collection of mixed-integer linear program (MILP) instances. Benchmark-specific submissions are encouraged (algorithms or trained ML models), but of course generic submissions that work for all three benchmarks are allowed.
Note: while we encourage solutions derived from the machine learning and reinforcement learning paradigms, any algorithmic solution respecting the competition's API is accepted.
Important dates (anywhere on earth time zone):
- Jul 1st '21 - competition start, release of the training datasets
- Oct 21st '21 - registration deadline, no new team is accepted past this date
- Oct 28th '21 - submission deadline, no submission is accepted past this date
- Nov 21st '21 - final result announcement and declaration of the winners
- Dec 9th '21 - virtual event at NeurIPS with poster session for all participants
- February '22 - official report with winner contributions, to be published in PMLR
This event is sponsored by the Artificial Intelligence Journal (AIJ), as well as Compute Canada, Calcul Québec and Westgrid who graciously provide the infrastructure and compute resources to run the competition.
Challenges
We propose three distinct challenges, each corresponding to a specific control task arising in traditional solvers. Participants can compete in any subset of those challenges, and one winner will be declared for each.
-
Primal task
Produce feasible solutions, in order to minimize the primal integral over time.
-
Dual task
Select branching variables, in order to minimize dual the dual integral over time.
-
Configuration task
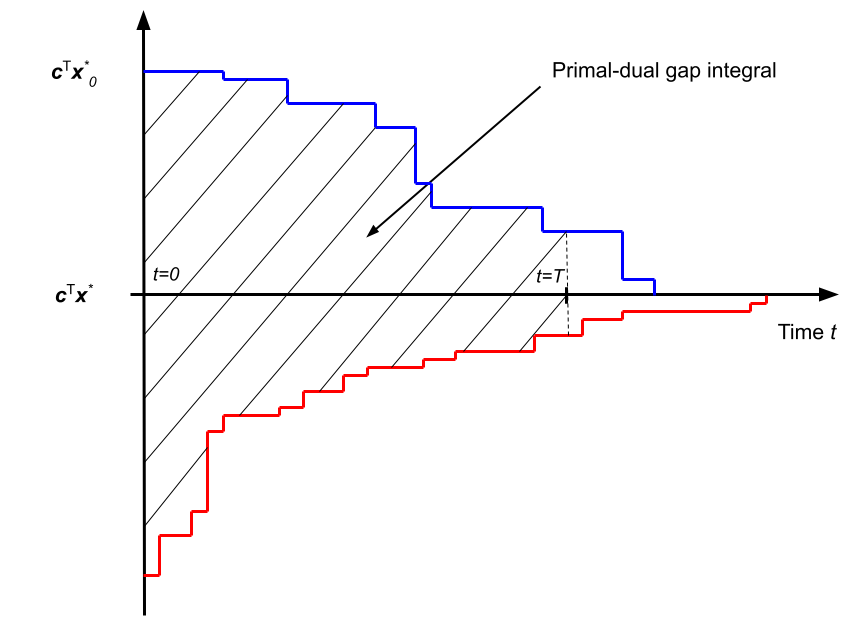
Choose the best solver parameters, in order to minimize the primal-dual integral over time.
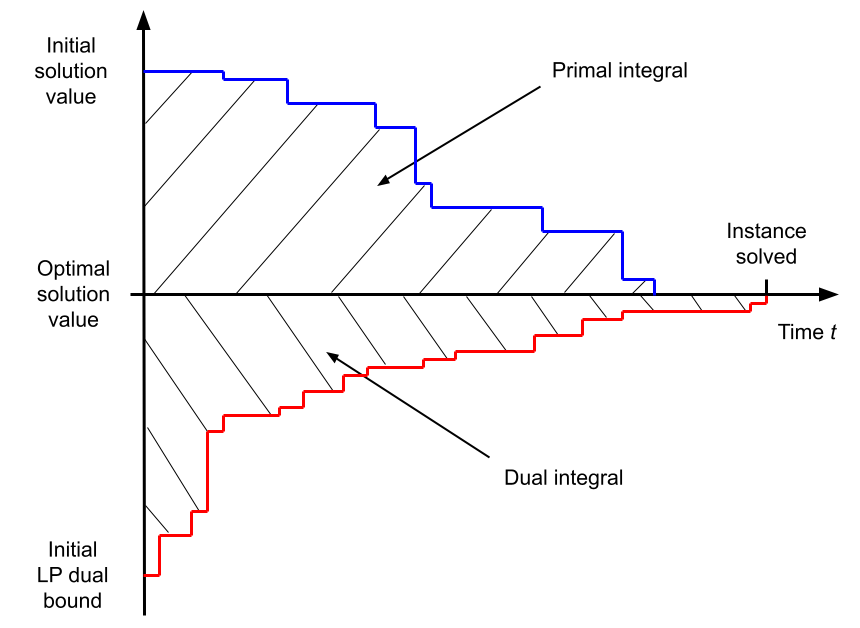
Primal and dual bounds evolution vs solving time
(for a minimization MILP instance).
Note that this figure
shows the primal and dual integrals minus
\(T\mathbf{c}^\top \mathbf{x}^\star\), which takes a
constant value for a particular instance.
Primal task - Finding feasible solutions
The primal task deals with finding good primal solutions at the root node of the branch-and-bound tree. To that end, the environment (SCIP solver) will not perform any branching but will enter an infinite loop at the root node, which will collect the agent's solutions, evaluate their feasibility, and update the overall best solution reached so far, thus lowering the current primal bound (upper bound). The metric of interest for this task is the primal integral, which takes into account the speed at which the primal bound decreases over time. To model a realistic scenario, each problem instance will have been preprocessed by SCIP (problem reduction, cutting planes etc.), and the root linear program (LP) relaxation will have been solved before the participants are asked to produce feasible solutions. To prevent SCIP from searching for primal solutions by itself, all primal heuristics will be deactivated. In order to compute this metric unambiguously, even when no solution has been found yet, we provide an initial primal bound (trivial solution value) for each instance, which is to be given to SCIP at the beginning of the solving process in the form of a user objective limit.
- Environment
- The solver is stopped at the root node after the root LP has been solved and enters an infinite loop. At each transition, the environment evaluates the given solution candidate and updates the primal bound. Nothing else happens. The solver remains in the SOLVING stage until the episode terminates (time limit reached, or when the problem is solved).
- Action
- A solution candidate for the current problem (variable assignment values, x).
- Metric
- Primal integral.
- Time limit
- \(T=5\) minutes.
- Relevant literature:
-
- Learning Combinatorial Optimization Algorithms over Graphs , Dai et al., NeurIPS'17
- Reinforcement Learning for Solving the Vehicle Routing Problem , Nazari et al., NeurIPS'18
- Combinatorial Optimization with Graph Convolutional Networks and Guided Tree Search , Li et al., NeurIPS'18
- Solving Mixed Integer Programs Using Neural Networks , Nair et al., 2020
Dual task - Branching
The dual task deals with obtaining tight optimality guarantees (dual bounds) via branching. Making good branching decisions is regarded as a critical component of modern branch-and-bound solvers, yet has received little theoretical understanding to this day (see Lodi et al., 2017). In this task, the environment will run a full-fledged branch-and-cut algorithm with SCIP, and the participants will only control the solver's branching decisions. The metric of interest is the dual integral, which considers the speed at which the dual bound increases over time. Also, all primal heuristics will be deactivated, so that the focus is only on proving optimality via branching.
- Environment
- Traditional branch-and-bound algorithm. The solver stops after each node is processed (LP solved), receives a branching decision, performs branching, and selects the next open node to process. The solver remains in the SOLVING stage until the episode terminates (time limit reached, or when the problem is solved).
- Action
- One of the current node's branching candidates (non-fixed integer variables). Only single-variable branching is allowed.
- Metric
- Dual integral.
- Time limit
- \(T=15\) minutes.
- Relevant literature:
-
- Learning to Branch in Mixed Integer Programming , Khalil et al., AAAI'16
- On Learning and Branching: a Survey , Lodi et al., TOP, 2017
- Learning to Branch , Balcan et al., ICML'18
- Exact Combinatorial Optimization with Graph Convolutional Neural Networks , Gasse et al., NeurIPS'19
- Hybrid Models for Learning to Branch , Gupta et al., NeurIPS'20
- Solving Mixed Integer Programs Using Neural Networks , Nair et al., 2020
Configuration task - Choosing solver parameters
The configuration task deals with deciding on a good parameterization of the solver for a given problem instance. The environment required for this task is more straightforward than for the two previous ones since it involves only a single decision for the agents (i.e., contextual bandit problem). Participants are allowed to tune any of the existing parameters of SCIP (except parameters regarding the computation of time). They can choose between providing a fixed set of parameters that work well on average for each problem benchmark or producing instance-specific parameterizations based on each instance's characteristics. The metric of interest for this task is the primal-dual gap integral, which combines both improvements from the dual and from the primal side over time. In order to compute this metric unambiguously, even when no primal or dual bound exists, we provide both an initial primal bound (trivial solution value) and an initial dual bound (pre-computed root LP solution value) for each instance.
- Environment
- The solver loads a problem instance and immediately stops. It then receives a parameterization, applies it, and pursues with the solving process until it terminates (time limit reached, or when the problem is solved). During the first and only transition, the solver is in the PROBLEM stage. As such, participants will not be able to extract advanced features from the solver, such as those relying on the LP being solved.
- Action
- A set of SCIP parameters, in the form of a key/value dictionary.
- Metric
- Primal-dual gap integral.
- Time limit
- \(T=15\) minutes.
- Relevant literature
-
- Sequential model-based optimization for general algorithm configuration , Hutter et al., LION'11
Metrics
Each of the three challenges, the primal task, the dual task and the configuration task, is associated with a specific evaluation metric that reflects a different objective. Here we describe how each metric is computed over a single problem instance, while the final goal of the participants is to optimize this metric in expectation over a hidden collection of test instances.
Because our evaluation metrics are time-dependent, all evaluations will be run on the same hardware setup, including one CPU core and one GPU card, which will be communicated at the start of the competition. For practical reasons, for each task, a maximum time budget \(T\) is given to process each test instance (5, 15 and 15 minutes respectively for the primal, dual and configuration tasks), after which the environment necessarily terminates. Participants should therefore focus on taking both good and fast decisions.
In the following we consider instances of mixed-integer linear programs (MILPs) expressed as follows: \[ \begin{eqnarray} \underset{\mathbf{x}}{\operatorname{arg\,min}} \quad \mathbf{c}^\top\mathbf{x} && \\ \text{subject to} \quad \mathbf{A}^\top\mathbf{x} & \leq & \mathbf{b} \text{,} \\ \mathbf{x} & \in & \mathbb{Z}^p \times \mathbb{R}^{n-p} \text{,} \end{eqnarray} \] where \(\mathbf{c} \in \mathbb{R}^n\) denotes the coefficients of the linear objective, \(\mathbf{A} \in \mathbb{R}^{m \times n}\) and \(\mathbf{b} \in \mathbb{R}^m\) respectively denote the coefficients and upper bounds of the linear constraints, while \(n\) is the total number of variables, \(p \leq n\) is the number of integer-constrained variables, and \(m\) the number of linear constraints.
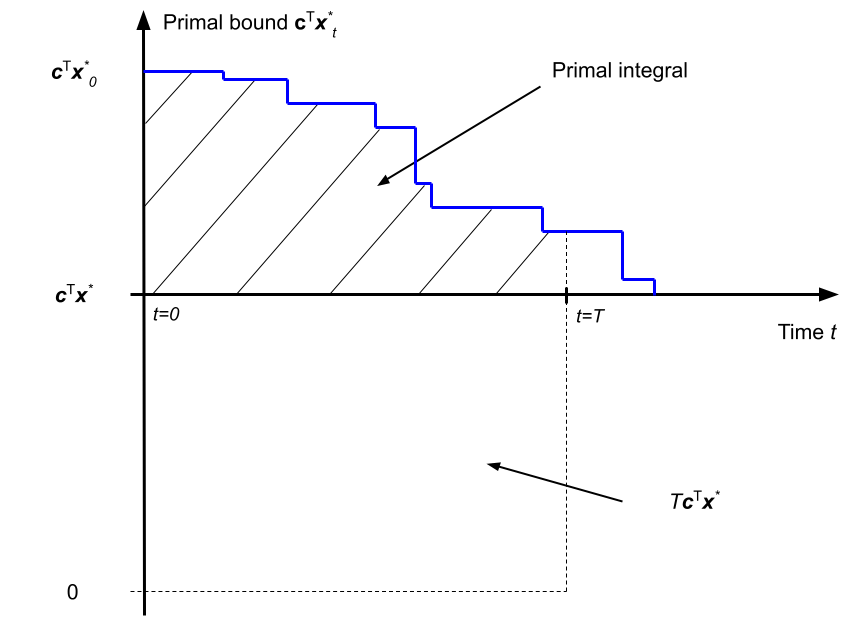
- Primal integral
-
This objective measures the area under the curve of the solver's primal bound (a.k.a. global upper bound), which corresponds to the value of the best feasible solution found so far. By providing better feasible solutions over time, the value of the primal bound decreases. With a time limit \(T\), the primal integral expresses as: \[ \int_{t=0}^{T} \mathbf{c}^\top \mathbf{x}^\star_t\;\mathrm{d}t - T\mathbf{c}^\top\mathbf{x}^\star \text{,} \] where \(\mathbf{x}^\star_t\) is the best feasible solution found at time \(t\) (so that \(\mathbf{c}^\top \mathbf{x}^\star_t\) is the primal bound at time \(t\)), and \(T\mathbf{c}^\top\mathbf{x}^\star\) is an instance-specific constant that depends on the optimal solution \(\mathbf{x}^\star\). The primal integral is to be minimized, and takes an optimal value of 0.
Note: to compute this metric unambiguously, a trivial initial solution \(x^\star_0\) is always provided to SCIP at the beginning of the solving process. Also, the constant term \(\mathbf{c}^\top\mathbf{x}^\star\) can be safely ignored at training time when participants train their control policy, as the learning problem is equivalent. At test time however, when we will evaluate the participant submissions, this constant term (or a proper substitute) will be incorporated in the reported metric.
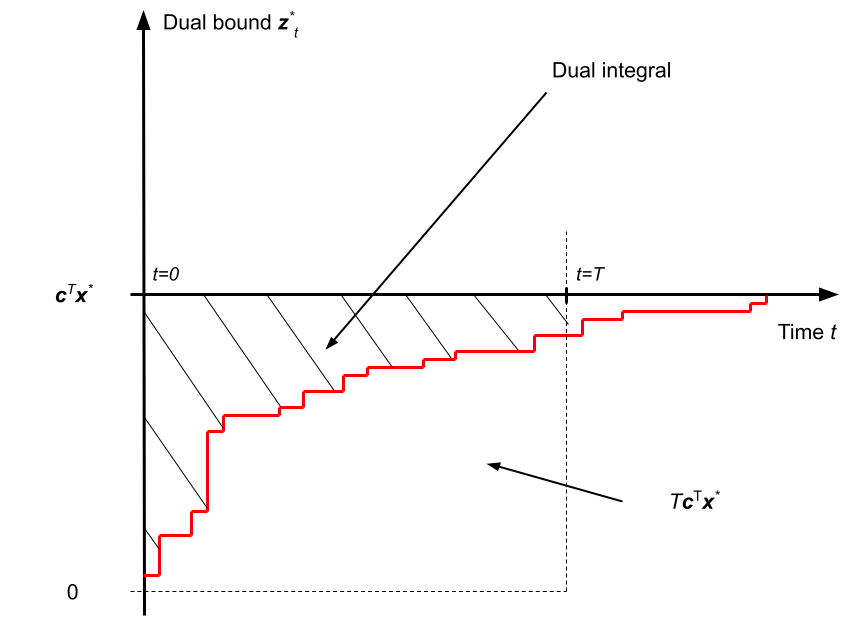
- Dual integral
-
This objective measures the area over the curve of the solver's dual bound (a.k.a. global lower bound), which usually corresponds to a solution of a valid relaxation of the MILP. By branching, the LP relaxations corresponding to the branch-and-bound tree leaves get tightened, and the dual bound increases over time. With a time limit \(T\), the dual integral expresses as: \[ T\mathbf{c}^\top\mathbf{x}^\star - \int_{t=0}^{T} \mathbf{z}^\star_t\;\mathrm{d}t \text{,} \] where \(\mathbf{z}^\star_t\) is the best dual bound at time \(t\), and \(T\mathbf{c}^\top\mathbf{x}^\star\) is an instance-specific constant that depends on the optimal solution value \(\mathbf{c}^\top\mathbf{x}^\star\). The dual integral is to be minimized, and takes an optimal value of 0.
Note: in the context of branching, this metric is unambiguous to compute, as the root node of the tree always provides an initial dual bound \(\mathbf{z}^*_0\) at the beginning of branching. Here again, the constant term \(\mathbf{c}^\top\mathbf{x}^\star\) can be safely ignored for training, but it will be incorporated (or a proper substitute) in the metrics that we will report when evaluating the participants submissions.
- Primal-dual gap integral
-
This objective measures the area between two curves, the solver's primal bound and the solver's dual bound. As such, this metric benefits both from improvements obtained from the primal side (finding good feasible solutions), and on the dual side (producing a tight optimality certificate). With a time limit \(T\), the primal-dual gap integral expresses as: \[ \int_{t=0}^{T} \mathbf{c}^\top \mathbf{x}^\star_t - \mathbf{z}^\star_t\;\mathrm{d}t \text{.} \] The primal-dual gap integral is to be minimized, and take an optimal value of 0.
Note: in the context of algorithm configuration, an initial value is required for the two curves at time \(t=0\). Therefore we always provide both an initial trivial solution \(x^\star_0\) and a valid initial dual bound \(z^\star_0\) to SCIP for this task.
Datasets
For each individual challenge, participants will be evaluated on three problem benchmarks from diverse application areas. Participants can provide a different decision-making code (algorithmic solution or trained ML model) for each of the benchmarks, or a single code that works for all benchmarks.
A problem benchmark consists in a collection of mixed-integer linear program (MILP) instances in the standard MPS file format. Each benchmark is split into a training and a test set, originating from the same problem distribution. While the training instances are made public at the beginning of the competition for participants to train their models, the test instances will be kept hidden for evaluation purposes and will only be revealed at the end of the competition.
Note: for each problem benchmark we suggest a pre-established split of the training instances into two distinct collections: train and valid. This is only a suggestion, and all instance files in both those collections can be likely considered as training instances. There is no restriction regarding how participants should use the provided instances during training.
The first two problem benchmarks are inspired by real-life applications of large-scale systems at Google, while the third benchmark is an anonymous problem inspired by a real-world, large-scale industrial application.
- Problem benchmark 1: Balanced Item Placement
- This problem deals with spreading items (e.g., files or processes) across containers (e.g., disks or machines) utilizing them evenly. Items can have multiple copies, but at most, one copy can be placed in a single bin. The number of items that can be moved is constrained, modeling the real-life situation of a live system for which some placement already exists. Each problem instance is modeled as a MILP, using a multi-dimensional multi-knapsack formulation. This dataset contains 10000 training instances (pre-split into 9900 train and 100 valid instances).
- Problem benchmark 2: Workload Apportionment
- This problem deals with apportioning workloads (e.g., data streams) across as few workers (e.g., servers) as possible. The apportionment is required to be robust to any one worker's failure. Each instance problem is modeled as a MILP, using a bin-packing with apportionment formulation. This dataset contains 10000 training instances (pre-split into 9900 train and 100 valid instances).
- Problem benchmark 3: Anonymous Problem
- The MILP instances corresponding to this benchmark are assembled from a public dataset, whose origin is kept secret to prevent cheating. Reverse-engineering for the purpose of recovering the test set is explicitly forbidden (see rules). This dataset contains 118 training instances (pre-split into 98 train and 20 valid instances).
Rules
The spirit of the competition is as follows:
- we encourage contributions from both the OR and ML communities by explicitly allowing non-ML submissions;
- we encourage student participation with a dedicated student leaderboard;
- we encourage original contributions by specifically making the use of highly-engineered commercial solvers prohibited.
Participants must adhere to the following rules:
- Eligibility
-
- Participants can work in teams.
- Participants can submit codes based on a machine learning model, a human-designed algorithm, or any combination of the two.
- Participants are not allowed to use commercial software in their code. The use of solvers such as CPLEX, Gurobi, or FICO XPress is explicitly forbidden.
- Student-only teams are eligible to a separate student leaderboard, in addition to the main leaderboard of the competition. A graduated PhD is not considered a student.
- Data
-
- The use of supplementary existing open-source datasets, e.g., for pre-training, is permitted provided they are credited.
- The use of private, proprietary datasets is not permitted.
- In order to prevent cheating, the evaluation data sets will be kept hidden to the participants during the competition.
- Participants are free and encouraged to extract original features from the solver for training and evaluation, though the Python interface of SCIP, PySCIPOpt.
- Submission
-
- The submitted codes must be written in Python, and must run in the evaluation environment which we provide.
- Parallel implementations using multiple processes or multiple threads are allowed, although the hardware on which the codes will be evaluated is single-core.
- The evaluation environment does not have access to any external network, to prevent any information leak.
- Users may make use of open source libraries given proper attribution. At the end of the competition, we encourage all code to be open-sourced so the results can be reproduced.
- The evaluation environment will provide a basic ML ecosystem (Tensorflow, Pytorch, Scikit-learn). Additional libraries will be added to the evaluation environment upon reasonable requests.
- At the end of the competition, the winners are expected to provide a description of the method they used.
- Cheating prevention
-
- Participants are forbidden to interact with the SCIP solver in any other way than the one intended, that is, extracting information or providing a control decision related to the task at hand. Any interaction with SCIP that results in changes of the solver's internal state will be considered cheating.
- Some datasets have been anonymized, as they rely on publicly accessible data. Any attempt at reverse-engineering for the purpose of recovering information about the test set is forbidden.
- Any instance of cheating, defined as violation of the rules above or any other attempt to circumvent the spirit and intent of the competition, as determined by the organizers, will result in the invalidation of all of the offending team’s submissions and a disqualification from the competition.
For each task, the winners will be declared as follows:
- Ranking rules
-
- Each team will be evaluated separately on each of the three benchmark datasets according the task's metric, i.e., primal integral, dual integral, or primal-dual integral. This metric will be averaged across all instances in the test dataset, resulting in an individual ranking for each dataset. For example, for the primal task, team A might obtain ranks 3, 8, 1 respectively in the three problem benchmark, while team B obtains ranks 2, 2, 15.
- Then, for each team those three ranks will be multiplied together to obtain the overall score of the team. For example, team A will obtain a score of 3x8x1=24 while team B obtains 2x2x15=60.
- The team with the lowest overall score wins.
Getting started
Registration form: register your team and subscribe to the competition's mailing list.
GitHub repository: get started and access the datasets, starter packages, and technical documentation.
Leaderboard
Those are the final results of the competition !
- Detailed evaluation results per instance for each team
-
Hidden evaluation instances (test set)
Note: the partial evaluations were using the first 20 instances (10000 to 10019) x 1 random seed for the item_placement and load_balancing benchmarks, and the first 4 instances (119 to 122) x 5 random seeds for the anonymous benchmark.
Note: for each challenge and each benchmark, we report two performance measures:
- the average evaluation metric (primal integral, dual integral, or primal-dual integral) obtained over the test instances, which is to be minimized. This measure is described in detail in the metrics section, and corresponds to the negated cumulated reward computed by our evaluation script, plus a constant term (\(T\mathbf{c}^\top\mathbf{x}^\star\), \(-T\mathbf{c}^\top\mathbf{x}^\star\) or \(0\)) that depends on the optimal solution value of each instance. Because for some instances it is hard to obtain the optimal solution value, and because this constant term is the same for every participant and does not impact the rankings, we compute an adequate estimate to substitute \(\mathbf{c}^\top\mathbf{x}^\star\) when the optimal solution value is not available, based on the best primal and dual bounds obtained after some time limit.
- the average cumulated reward (cum. reward) obtained over the test instances, which is to be maximized. We report this measure for information purposes, as it is exactly the one computed by our evaluation script. This measure can be interpreted as the negated and unshifted version of the evaluation metric (it does not depend on \(\mathbf{c}^\top\mathbf{x}^\star\)), and it produces the exact same ranking.
Global leaderboard
Primal task| rank | team | item_placement | load_balancing | anonymous | score | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| primal integral | (cum. reward) | rank | primal integral | (cum. reward) | rank | primal integral | (cum. reward) | rank | |||
| 1 | CUHKSZ_ATD | 358.43 | (-3355.56) | 1 | 1145.31 | (-213467.31) | 1 | 35220755.00 | (-45747908.15) | 1 | 1 |
| 2 | UNIST-LIM-Lab | 2905.14 | (-5902.27) | 5 | 2374.55 | (-214696.55) | 2 | 38163724.79 | (-48690877.94) | 2 | 20 |
| 3 | MDO | 1801.37 | (-4798.50) | 3 | 3731.14 | (-216053.14) | 3 | 42083527.25 | (-52610680.40) | 3 | 27 |
| 4 | EI-OROAS | 1102.19 | (-4099.32) | 2 | 5421.57 | (-217743.57) | 4 | 90785744.12 | (-101312897.27) | 4 | 32 |
| 5 | Mr_Tree | 2991.59 | (-5988.72) | 7 | 6129.95 | (-218451.95) | 5 | 101674814.40 | (-112201967.54) | 5 | 175 |
| 6 | MILPandCookies | 1988.99 | (-4986.12) | 4 | 8668.15 | (-220990.15) | 7 | 217199453.09 | (-227726606.23) | 9 | 252 |
| 7 | generaleyes | 2927.08 | (-5924.21) | 6 | 6727.64 | (-219049.64) | 6 | 148125214.44 | (-158652367.58) | 8 | 288 |
| 8 | Nuri | 3845.90 | (-6843.03) | 9 | 9971.47 | (-222293.47) | 8 | 146534189.23 | (-157061342.38) | 6 | 432 |
| 9 | MixedInspiringLamePuns | 3751.95 | (-6749.08) | 8 | 19227.29 | (-231549.29) | 11 | 147249230.60 | (-157776383.75) | 7 | 616 |
| 10 | dt | 3990.36 | (-6987.49) | 11 | 10020.24 | (-222342.24) | 9 | nan | (nan) | 11 | 1089 |
| 11 | ethz-scuba | 3851.41 | (-6848.54) | 10 | 10097.26 | (-222419.26) | 10 | nan | (nan) | 11 | 1100 |
| 12 | nf-lzg | 185411.53 | (-188408.66) | 12 | 56093.61 | (-268415.61) | 12 | 217206293.12 | (-227733446.26) | 10 | 1440 |
| rank | team | item_placement | load_balancing | anonymous | score | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| dual integral | (cum. reward) | rank | dual integral | (cum. reward) | rank | dual integral | (cum. reward) | rank | |||
| 1 | Nuri | 2307.39 | (6684.00) | 1 | 6178.82 | (630787.18) | 6 | 3770677.01 | (27810782.42) | 1 | 6 |
| 2 | EI-OROAS | 2321.09 | (6670.30) | 2 | 5221.69 | (631744.31) | 1 | 4423016.69 | (27158442.74) | 4 | 8 |
| 3 | EFPP | 2503.86 | (6487.53) | 3 | 5600.98 | (631365.02) | 3 | 5241194.97 | (26340264.47) | 13 | 117 |
| 4 | KAIST_OSI | 2794.83 | (6196.56) | 7 | 5555.42 | (631410.58) | 2 | 4955048.57 | (26626410.86) | 9 | 126 |
| 5 | qqy | 2614.16 | (6377.23) | 6 | 6408.69 | (630557.31) | 11 | 4359960.40 | (27221499.03) | 2 | 132 |
| 6 | DaShun | 4172.32 | (4819.07) | 14 | 6067.75 | (630898.25) | 4 | 4430033.29 | (27151426.15) | 5 | 280 |
| 7 | lxj24 | 2547.84 | (6443.55) | 4 | 6812.76 | (630153.24) | 19 | 4529137.95 | (27052321.48) | 7 | 532 |
| 8 | null_ | 4326.88 | (4664.51) | 16 | 6667.65 | (630298.35) | 14 | 4397369.92 | (27184089.51) | 3 | 672 |
| 9 | Superfly | 2967.19 | (6024.20) | 9 | 6219.04 | (630746.96) | 9 | 5208108.44 | (26373350.99) | 10 | 810 |
| 10 | comeon | 3064.84 | (5926.55) | 11 | 6215.34 | (630750.66) | 8 | 5234475.79 | (26346983.64) | 12 | 1056 |
| 11 | Monkey | 3012.74 | (5978.65) | 10 | 6228.15 | (630737.85) | 10 | 5211351.55 | (26370107.88) | 11 | 1100 |
| 12 | ark | 2571.48 | (6419.91) | 5 | 6551.55 | (630414.45) | 12 | 6047785.19 | (25533674.24) | 19 | 1140 |
| 13 | KEP-UNIST | 4217.28 | (4774.10) | 15 | 6668.28 | (630297.72) | 15 | 4496064.97 | (27085394.46) | 6 | 1350 |
| 14 | blueterrier | 4406.55 | (4584.84) | 17 | 6139.67 | (630826.33) | 5 | 5441474.12 | (26139985.31) | 16 | 1360 |
| 15 | THUML-RL | 3896.03 | (5095.36) | 12 | 6766.29 | (630199.71) | 18 | 4757445.44 | (26824014.00) | 8 | 1728 |
| 16 | nf-lzg | 2913.67 | (6077.72) | 8 | 6638.52 | (630327.48) | 13 | 6573990.84 | (25007468.59) | 22 | 2288 |
| 17 | gentlemenML4CO | 4523.89 | (4467.50) | 18 | 6213.06 | (630752.94) | 7 | 6466016.68 | (25115442.76) | 20 | 2520 |
| 18 | CUHKSZ_ATD | 3915.39 | (5076.00) | 13 | 6718.59 | (630247.41) | 16 | 5573897.19 | (26007562.25) | 17 | 3536 |
| 19 | wanghaha | nan | (nan) | 22 | nan | (nan) | 22 | 5274947.22 | (26306512.21) | 14 | 6776 |
| 20 | Columbia_Combinators | 4777.53 | (4213.86) | 19 | 6950.29 | (630015.71) | 20 | 5645454.36 | (25936005.08) | 18 | 6840 |
| 21 | uofx | 4837.90 | (4153.49) | 20 | 6758.59 | (630207.41) | 17 | 6494813.82 | (25086645.61) | 21 | 7140 |
| 22 | shg | nan | (nan) | 22 | nan | (nan) | 22 | 5320942.08 | (26260517.36) | 15 | 7260 |
| 23 | sylvia | nan | (nan) | 22 | nan | (nan) | 22 | nan | (nan) | 23 | 11132 |
| rank | team | item_placement | load_balancing | anonymous | score | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| primal-dual integral | (cum. reward) | rank | primal-dual integral | (cum. reward) | rank | primal-dual integral | (cum. reward) | rank | |||
| 1 | EI-OROAS | 8740.86 | (-8740.86) | 1 | 7855.99 | (-7855.99) | 1 | 171885235.63 | (-171885235.63) | 1 | 1 |
| 2 | MDO | 11921.54 | (-11921.54) | 2 | 10024.53 | (-10024.53) | 2 | 302525715.45 | (-302525715.45) | 8 | 32 |
| 3 | MixedInspiringLamePuns | 13921.83 | (-13921.83) | 8 | 15273.77 | (-15273.77) | 3 | 243147957.58 | (-243147957.58) | 2 | 48 |
| 4 | KEP-UNIST | 14235.59 | (-14235.59) | 9 | 21295.63 | (-21295.63) | 7 | 244674037.59 | (-244674037.59) | 3 | 189 |
| 5 | MOEA | 13708.30 | (-13708.30) | 7 | 19825.74 | (-19825.74) | 5 | 316664072.25 | (-316664072.25) | 9 | 315 |
| 6 | KAIST_OSI | 14295.26 | (-14295.26) | 10 | 27581.54 | (-27581.54) | 11 | 280221086.37 | (-280221086.37) | 4 | 440 |
| 7 | Cho | 14916.76 | (-14916.76) | 11 | 19375.92 | (-19375.92) | 4 | 319244049.27 | (-319244049.27) | 11 | 484 |
| 8 | EasyML | 13540.06 | (-13540.06) | 5 | 31567.51 | (-31567.51) | 12 | 317773267.64 | (-317773267.64) | 10 | 600 |
| 8 | shg | 16800.60 | (-16800.60) | 12 | 26440.38 | (-26440.38) | 10 | 291713566.26 | (-291713566.26) | 5 | 600 |
| 10 | nf-lzg | 13512.81 | (-13512.81) | 4 | 31744.61 | (-31744.61) | 13 | 320912948.54 | (-320912948.54) | 12 | 624 |
| 10 | THUML-RL | 16813.71 | (-16813.71) | 13 | 22302.65 | (-22302.65) | 8 | 291950394.33 | (-291950394.33) | 6 | 624 |
| 12 | null_ | 18044.01 | (-18044.01) | 15 | 20671.55 | (-20671.55) | 6 | 299993131.56 | (-299993131.56) | 7 | 630 |
| 12 | DaShun | 12225.81 | (-12225.81) | 3 | 47906.58 | (-47906.58) | 14 | nan | (nan) | 15 | 630 |
| 14 | ECNUNoah001 | 13600.63 | (-13600.63) | 6 | 22822.54 | (-22822.54) | 9 | 352732751.49 | (-352732751.49) | 13 | 702 |
| 15 | Nuri | 17959.96 | (-17959.96) | 14 | 176276.05 | (-176276.05) | 15 | 658515478.10 | (-658515478.10) | 14 | 2940 |
Student leaderboard
Primal task| rank | team | item_placement | load_balancing | anonymous | score | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| primal integral | (cum. reward) | rank | primal integral | (cum. reward) | rank | primal integral | (cum. reward) | rank | |||
| 1 | UNIST-LIM-Lab | 2905.14 | (-5902.27) | 1 | 2374.55 | (-214696.55) | 1 | 38163724.79 | (-48690877.94) | 1 | 1 |
| 2 | MixedInspiringLamePuns | 3751.95 | (-6749.08) | 2 | 19227.29 | (-231549.29) | 3 | 147249230.60 | (-157776383.75) | 2 | 12 |
| 3 | ethz-scuba | 3851.41 | (-6848.54) | 3 | 10097.26 | (-222419.26) | 2 | nan | (nan) | 4 | 24 |
| 4 | nf-lzg | 185411.53 | (-188408.66) | 4 | 56093.61 | (-268415.61) | 4 | 217206293.12 | (-227733446.26) | 3 | 48 |
| rank | team | item_placement | load_balancing | anonymous | score | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| dual integral | (cum. reward) | rank | dual integral | (cum. reward) | rank | dual integral | (cum. reward) | rank | |||
| 1 | qqy | 2614.16 | (6377.23) | 3 | 6408.69 | (630557.31) | 3 | 4359960.40 | (27221499.03) | 1 | 9 |
| 2 | KAIST_OSI | 2794.83 | (6196.56) | 4 | 5555.42 | (631410.58) | 1 | 4955048.57 | (26626410.86) | 5 | 20 |
| 3 | lxj24 | 2547.84 | (6443.55) | 1 | 6812.76 | (630153.24) | 8 | 4529137.95 | (27052321.48) | 3 | 24 |
| 4 | ark | 2571.48 | (6419.91) | 2 | 6551.55 | (630414.45) | 4 | 6047785.19 | (25533674.24) | 9 | 72 |
| 4 | comeon | 3064.84 | (5926.55) | 6 | 6215.34 | (630750.66) | 2 | 5234475.79 | (26346983.64) | 6 | 72 |
| 6 | null_ | 4326.88 | (4664.51) | 8 | 6667.65 | (630298.35) | 6 | 4397369.92 | (27184089.51) | 2 | 96 |
| 7 | THUML-RL | 3896.03 | (5095.36) | 7 | 6766.29 | (630199.71) | 7 | 4757445.44 | (26824014.00) | 4 | 196 |
| 8 | nf-lzg | 2913.67 | (6077.72) | 5 | 6638.52 | (630327.48) | 5 | 6573990.84 | (25007468.59) | 10 | 250 |
| 9 | Columbia_Combinators | 4777.53 | (4213.86) | 9 | 6950.29 | (630015.71) | 9 | 5645454.36 | (25936005.08) | 8 | 648 |
| 10 | wanghaha | nan | (nan) | 10 | nan | (nan) | 10 | 5274947.22 | (26306512.21) | 7 | 700 |
| 11 | sylvia | nan | (nan) | 10 | nan | (nan) | 10 | nan | (nan) | 11 | 1100 |
| rank | team | item_placement | load_balancing | anonymous | score | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| primal-dual integral | (cum. reward) | rank | primal-dual integral | (cum. reward) | rank | primal-dual integral | (cum. reward) | rank | |||
| 1 | MixedInspiringLamePuns | 13921.83 | (-13921.83) | 4 | 15273.77 | (-15273.77) | 1 | 243147957.58 | (-243147957.58) | 1 | 4 |
| 2 | MOEA | 13708.30 | (-13708.30) | 3 | 19825.74 | (-19825.74) | 2 | 316664072.25 | (-316664072.25) | 5 | 30 |
| 3 | nf-lzg | 13512.81 | (-13512.81) | 1 | 31744.61 | (-31744.61) | 7 | 320912948.54 | (-320912948.54) | 7 | 49 |
| 4 | KAIST_OSI | 14295.26 | (-14295.26) | 5 | 27581.54 | (-27581.54) | 5 | 280221086.37 | (-280221086.37) | 2 | 50 |
| 5 | EasyML | 13540.06 | (-13540.06) | 2 | 31567.51 | (-31567.51) | 6 | 317773267.64 | (-317773267.64) | 6 | 72 |
| 5 | THUML-RL | 16813.71 | (-16813.71) | 6 | 22302.65 | (-22302.65) | 4 | 291950394.33 | (-291950394.33) | 3 | 72 |
| 7 | null_ | 18044.01 | (-18044.01) | 7 | 20671.55 | (-20671.55) | 3 | 299993131.56 | (-299993131.56) | 4 | 84 |
Competition Proceedings
Main paper (with winner contributions)
(Please cite this when refering to the competition)
The Machine Learning for Combinatorial Optimization Competition (ML4CO): Results and Insights
Maxime Gasse, Simon Bowly, Quentin Cappart, Jonas Charfreitag, Laurent Charlin, Didier Chételat, Antonia Chmiela, Justin Dumouchelle, Ambros Gleixner, Aleksandr M. Kazachkov, Elias Khalil, Pawel Lichocki, Andrea Lodi, Miles Lubin, Chris J. Maddison, Morris Christopher, Dimitri J. Papageorgiou, Augustin Parjadis, Sebastian Pokutta, Antoine Prouvost, Lara Scavuzzo, Giulia Zarpellon, Linxin Yang, Sha Lai, Akang Wang, Xiaodong Luo, Xiang Zhou, Haohan Huang, Shengcheng Shao, Yuanming Zhu, Dong Zhang, Tao Quan, Zixuan Cao, Yang Xu, Zhewei Huang, Shuchang Zhou, Chen Binbin, He Minggui, Hao Hao, Zhang Zhiyu, An Zhiwu, Mao Kun
Proceedings of the NeurIPS 2021 Competitions and Demonstrations Track, PMLR 176:220-231, 2022.
Contributed papers
- Confidence Threshold Neural Diving by Taehyun Yoon.
- Efficient Primal Heuristics for Mixed-Integer Linear Programs by Akang Wang, Linxin Yang, Sha Lai, Xiaodong Luo, Xiang Zhou, Haohan Huang, Shengcheng Shao, Yuanming Zhu, Dong Zhang, Tao Quan.
- Instance-wise algorithm configuration with graph neural networks by Romeo Valentin, Claudio Ferrari, Jérémy Scheurer, Andisheh Amrollahi, Chris Wendler, Max B. Paulus.
- MDO’s Method for NeurIPS 2021 ML4CO’s Configuration Task by Mengyuan Zhang.
- ML4CO: Is GCNN All You Need? Graph Convolutional Neural Networks Produce Strong Baselines For Combinatorial Optimization Problems, If Tuned and Trained Properly, on Appropriate Data by Amin Banitalebi-Dehkordi, Yong Zhang.
- ML4CO submission EFPP by Edward Lam, Frits de Nijs, Pierre Le Bodic, Peter J. Stuckey.
- ML4CO-KIDA: Knowledge Inheritance in Dataset Aggregation by Zixuan Cao, Yang Xu, Zhewei Huang, Shuchang Zhou.
- Strong Regularization is All You Need: Toward ML4CO Challenge by Seungjoon Park, Minu Kim, Minchan Jeong, Yejin Cho, Mingyu Kim.
- YORDLE: An Efficient Imitation Learning for Branch and Bound by Qingyu Qu, Xijun Li, Yunfan Zhou.
List of participants
Primal task
- CUHKSZ_ATD
- Xiaodong Luo, Shenzhen Research Institute of Big Data
- Akang Wang, Shenzhen Research Institute of Big Data
- Zhang Dong, Huawei GTS
- Sha Lai, Shenzhen Research Institute of Big Data
- Tao Quan, Huawei GTS
- Shengcheng Shao, Huawei GTS
- Xiang Zhou, Huawei GTS
- Yuanming Zhu, Huawei GTS
- Linxin Yang, Shenzhen Research Institute of Big Data
- Haohan Huang, Huawei GTS
- dt
- Ding Tong, Huawei Technologies Co., Ltd.
- Zhang Zhiyu, Huawei Technologies Co., Ltd.
- EasyML
- Zhendong Zhang, Xidian University
- EI-OROAS
- Wang pan, Huawei Cloud Computing Technologies Co., Ltd.
- Chen Zihan, Huawei Cloud Computing Technologies Co., Ltd.
- Zhang Zhiyu, Huawei Cloud Computing Technologies Co., Ltd.
- He Minggui, Huawei Cloud Computing Technologies Co., Ltd.
- Hou Zongfu, University of Chinese Academy of Sciences
- Chen Binbin, TsingHua University
- ethz-scuba
- Daniel Paleka, ETH Zurich
- Carla Rieger, ETH Zurich
- Max Paulus, ETH Zurich
- generaleyes
- Kushal Tirumala, Caltech
- Anirudh Rangaswamy, Caltech
- Jialin Song, Caltech
- MDO
- Mou Sun, Alibaba DAMO Academy
- Lei Zhou, Tongji University
- Jialin Liu, Alibaba DAMO Academy
- MILPandCookies
- Natalia Summerville, SAS Institute
- Rob Pratt, SAS
- Matt Galati, SAS
- Jorge Silva, SAS
- Laci Ladanyi, SAS
- Phillip Christophel, SAS
- MixedInspiringLamePuns
- Carla Rieger, ETH Zurich
- Federico Gossi, ETH Zurich
- Max B. Paulus, ETH Zurich
- Mr_Tree
- Jianshu Li, Huawei Co.
- nf-lzg
- Fei Ni, Tianjin University
- Zhigang Li, Tianjin University
- Nuri
- Zixuan Cao, Peking University
- Yang Xu, Peking University
- Zhewei Huang, Megvii
- Shuchang Zhou, Megvii
- UNIST-LIM-Lab
- Taehyun Yoon, Ulsan National Institute of Science and Techonology
Dual task
- ark
- Ark Zhu, Soochow University
- blueterrier
- Pooja Pandey, 1QB Information Technologies, Inc
- Kyle Mills, 1QB Information Technologies, Inc
- Columbia_Combinators
- Wentao Zhao, Columbia University
- Abhi Gupta, Columbia University
- Yunhao Tang, Columbia University
- Sian Lee, Columbia University
- Amey Pasarkar, Columbia University
- Luocen Wang, Columbia University
- comeon
- Jingbo Sun, Beijing Institute of Technology
- Zhiqiang He, Northeastern University
- CUHKSZ_ATD
- Xiaodong Luo, Shenzhen Research Institute of Big Data
- Akang Wang, Shenzhen Research Institute of Big Data
- Linxin Yang, Shenzhen Research Institute of Big Data
- Sha Lai, Shenzhen Research Institute of Big Data
- Zhang Dong (张栋), Huawei GTS
- Quan Tao (权涛)
- Chen Juan (陈娟)
- Shao Shengcheng (邵晟程), Huawei GTS
- Xiang Zhou (周祥), Huawei GTS
- Huang Hiroshi (黄浩瀚)
- Wang Haomao (王浩茂)
- Zhu Yuanming (朱元明), Huawei GTS
- DaShun
- Zhi Wang, Ant Group
- EasyML
- Zhendong Zhang, Xidian University
- EI-OROAS
- Amin Banitalebi-Dehkordi, Huawei Technologies Canada Co., Ltd.
- Yusi Ye, Huawei Technologies
- Tianyu Zhang, Huawei Technologies Canada Co., Ltd.
- Zirui Zhou, Huawei Technologies Canada Co., Ltd.
- Yong Zhang, Huawei Technologies Canada Co., Ltd.
- gentlemenML4CO
- Wenqing Zheng, UT Austin
- Haoyu Wang, Purdue
- Peihao Wang, UT Austin
- Tianlong Chen, UT Austin
- Xiaohan Chen, UT Austin
- Zhangyang Wang, UT Austin
- Pan Li, Purdue
- KAIST_OSI
- Seungjoon Park, KAIST
- Mingyu Kim, KAIST
- Minchan Jeong, KAIST
- Minu Kim, KAIST
- Yejin Cho, KAIST
- KEP-UNIST
- Jinwon Choi, Kakaoenterprise
- Hyunho Lee, Kakaoenterprise
- Kyushik Min, Kakaoenterprise
- Minsub Lee, UNIST
- Keehun Park, UNIST
- Hanbum Ko, UNIST
- lxj24
- Xijun Li, University of Science and Technology of China
- Monkey
- Jingbo Sun
- Zhiqiang He
- Xiaomin Yuan
- nf-lzg
- Fei Ni, Tianjin University
- Zhigang Li, Tianjin University
- null_
- Jiaxuan He, Tsinghua University
- Nuri
- Zixuan Cao, Peking University
- Yang Xu, Peking University
- Zhewei Huang, Megvii
- Shuchang Zhou, Megvii
- qqy
- Qingyu Qu, Beihang University
- shg
- Rang Jun, GuiZhou University
- Superfly
- Yafei Zhang
- sylvia
- THUML-RL
- Jincheng Zhong, Tsinghua University
- Jialong Wu, Tsinghua University
- Haoyu Ma, Tsinghua University
- uofx
- wanghaha
- Wang Haha
Configuration task
- Cho
- Hyunsoo Cho, Pusan National University
- DaShun
- Zhi Wang, Ant Group
- Qi Zhang, Ant Group
- EasyML
- Zhendong Zhang, Xidian University
- ECNUNoah001
- Hao Hao, East China Normal University
- EFPP
- Edward Lam, Monash University
- Frits de Nijs, Monash University
- Pierre Le Bodic, Monash University
- Peter Stuckey, Monash University
- EI-OROAS
- Chen Binbin, TsingHua University
- He Minggui, Huawei Cloud Computing Technologies Co., Ltd.
- Hao Hao, Huawei Noah's ark lab
- Zhang Zhiyu, Huawei Cloud Computing Technologies Co., Ltd.
- An Zhiwu, Huawei Cloud Computing Technologies Co., Ltd.
- Mao Kun, Huawei Cloud Computing Technologies Co., Ltd.
- KAIST_OSI
- Seungjoon Park, KAIST
- Mingyu Kim, KAIST
- Minchan Jeong, KAIST
- Minu Kim, KAIST
- Yejin Cho, KAIST
- KEP-UNIST
- Jinwon Choi, Kakaoenterprise
- Hyunho Lee, Kakaoenterprise
- Kyushik Min, Kakaoenterprise
- Minsub Lee, UNIST
- Keehun Park, UNIST
- Hanbum Ko, UNIST
- MDO
- Mengyuan Zhang, Alibaba DAMO Academy
- MixedInspiringLamePuns
- Romeo Valentin, ETH Zurich
- Claudio Ferrari, ETH Zurich
- Jeremy Scheuer, ETH Zurich
- Andisheh Amrollahi, ETH Zurich
- Chris Wendler, ETH Zurich
- Max B. Paulus, ETH Zurich
- MOEA
- Wang Shuai, East China Normal University
- nf-lzg
- Fei Ni, Tianjin University
- Zhigang Li, Tianjin University
- null_
- Jiaxuan He, Tsinghua University
- Nuri
- Zixuan Cao, Peking University
- Yang Xu, Peking University
- Zhewei Huang, Megvii
- Shuchang Zhou, Megvii
- shg
- Rang Jun, GuiZhou University
- THUML-RL
- Jincheng Zhong, Tsinghua University
- Jialong Wu, Tsinghua University
- Haoyu Ma, Tsinghua University